



通过langchain + gradio仅用百行python代码即可实现一个简易的RAG应用。本文将以《三体》为例,解读实现步骤。
什么是RAG?
Retrieval Augmented Generation (RAG)是一种增强LLM针对特定信息推理能力的方法。LLM,如chatgpt,一般是在某个机构使用特定时间的数据集进行训练得到的模型,而当我们需要对特定领域的信息或私密信息进行问答时,它就难以给出准确答案了。例如直接让chatgpt介绍一下三体中章北海的所作所为,就会得到以下结果:

这种情况下用已有的数据重新微调大模型代价很大,且难以做到实时的效果,而RAG很好地解决了该问题。
如何实现RAG?
实现一个RAG应用一般分为两步:建立索引和检索生成。
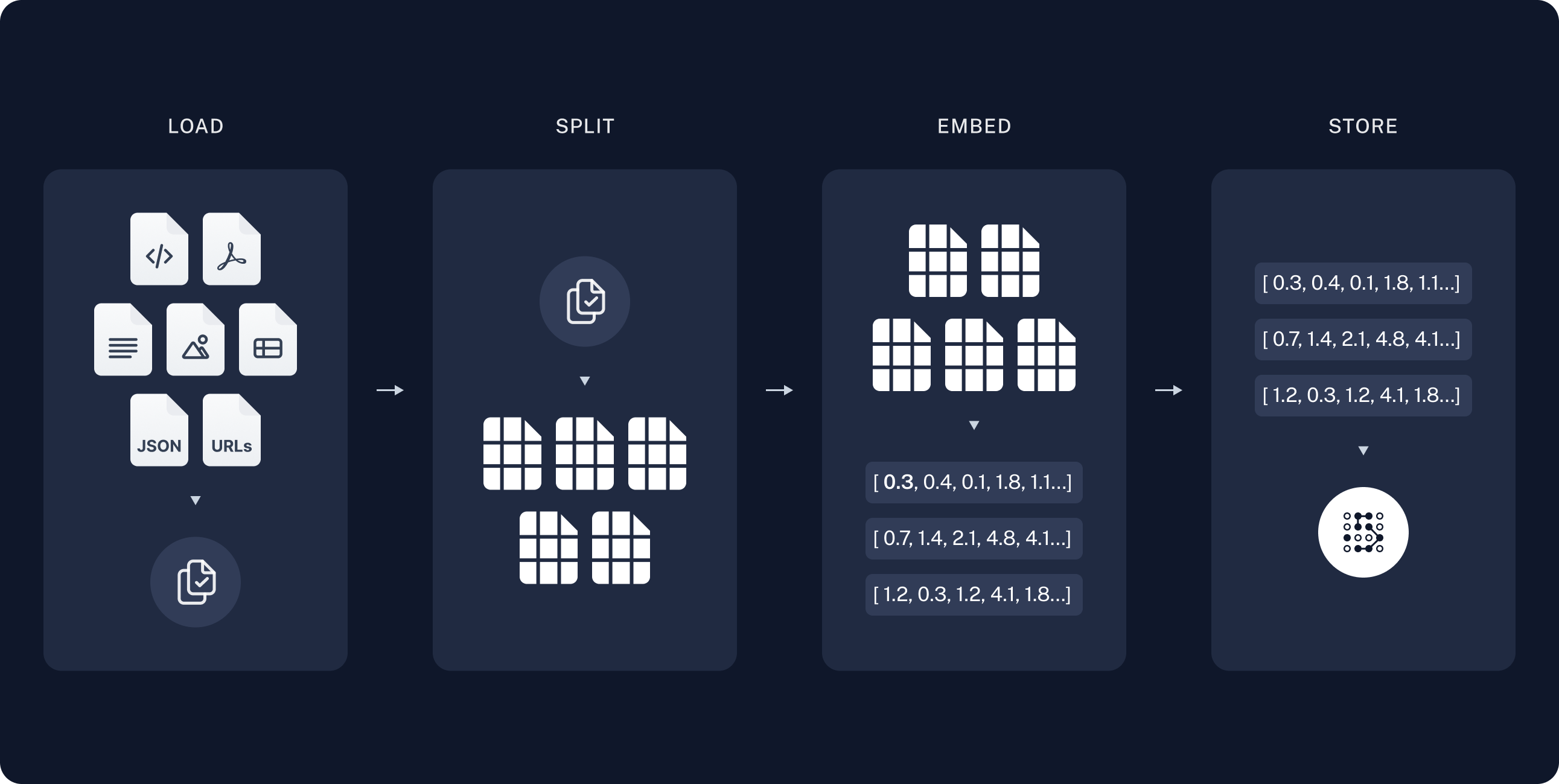
建立索引
通过Embedding模型将源数据转换为词向量保存至向量数据库中,通常有以下步骤:
- Load: 首先使用DocumentLoader读取不同类型的文档数据。
- Split: 然后将文档按一定规则分割为较小的块(chunk). 以便于模型能够更好的进行上下文理解。
- Store: 最后通过Embedding模型将分割出来的块映射为向量,并存储在向量数据库中,以便于检索。
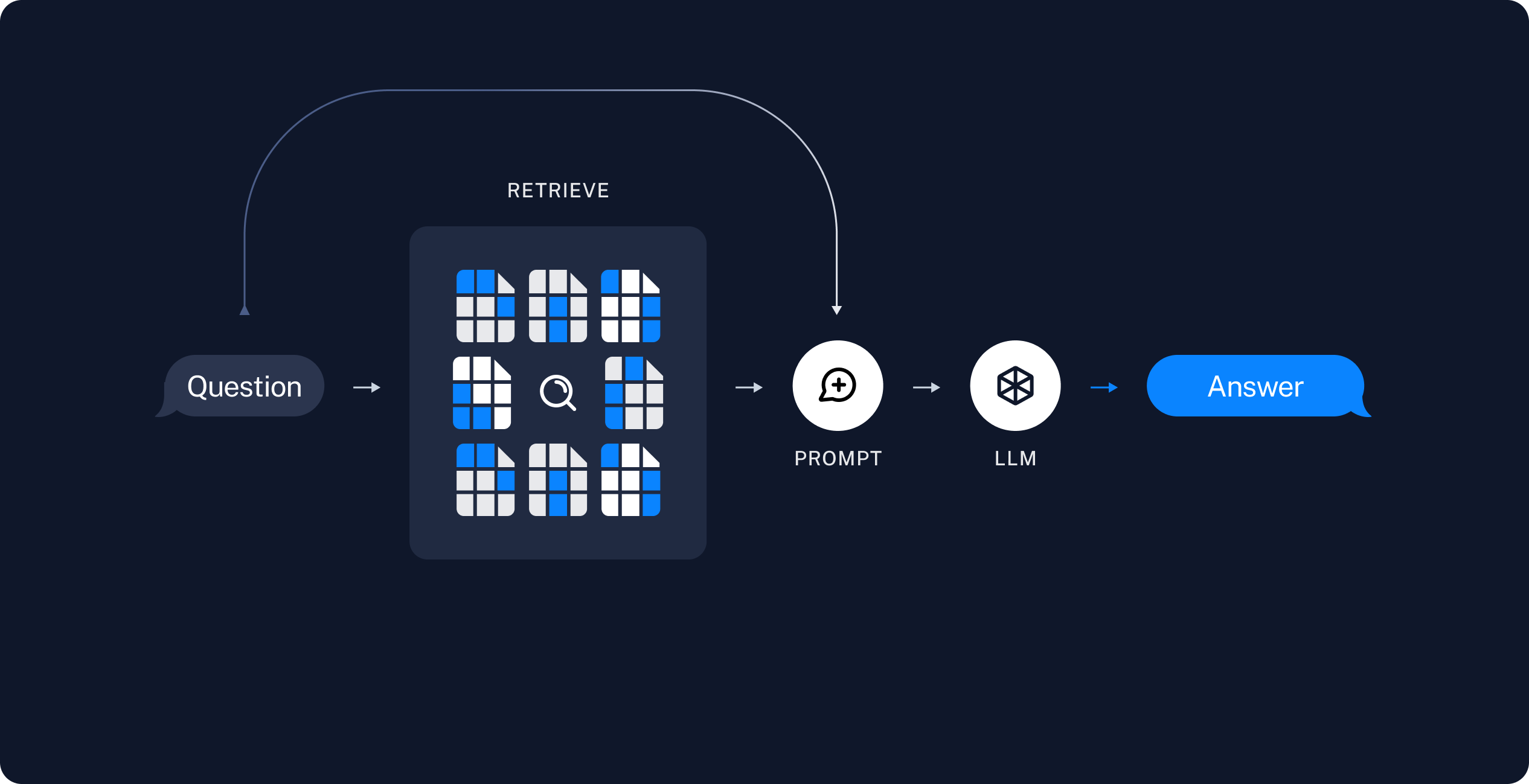
检索生成
实际这是两个步骤:
- Retrieve: 将用户输入的问题也转换为词向量,并在向量数据库中检索相关性最高的块。
- Generate: 使用ChatModel 或 LLM,如chatgpt,根据用户的问题基于特定的prompt对检索到的内容生成摘要。
什么是langchain?
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
什么是gradio?
Gradio是一个用于快速构建交互式应用程序的开源Python库。它可以帮助开发者轻松地将机器学习模型集成到用户友好的界面中,从而使模型更易于使用和理解。
使用langchain+gradio快速实现一个三体问答机器人
项目源码已发布至GitHub:https://github.com/zivenyang/3body-chatbot 以下是核心代码(由于当时国内难以申请openai账号,故使用的Azure Openai的api)
from dotenv import load_dotenv
from langchain.chat_models import AzureChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.vectorstores import Chroma
from langchain.embeddings import ModelScopeEmbeddings
from langchain.document_loaders import TextLoader, DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import gradio as gr
import os
# 导入.env中的变量,AZURE_OPENAI_ENDPOINT和AZURE_OPENAI_API_KEY
load_dotenv()
# 词嵌入模型,因为是中文小说,所以使用的达摩院训练的中文词嵌入模型
MODEL_ID = "damo/nlp_gte_sentence-embedding_chinese-base"
# 向量数据库存储路径
PERSIST_DIRECTORY = 'docs/chroma/'
# 为了在控制台同时输出索引文档和答案,不然会报错
class AnswerConversationBufferMemory(ConversationBufferMemory):
def save_context(self, inputs, outputs) -> None:
return super(AnswerConversationBufferMemory, self).save_context(inputs,{'response': outputs['answer']})
def create_db():
"""读取本地文件并生成词向量存入向量数据库"""
# 读取本地文件,即三体小说
text_loader_kwargs={'autodetect_encoding': True}
loader = DirectoryLoader("./docs", glob="**/*.txt", loader_cls=TextLoader, loader_kwargs=text_loader_kwargs)
pages = loader.load()
# 文件分块,chunk_size与也与显卡性能有关,显存越大分的越细
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 512,
chunk_overlap = 0,
length_function = len,
)
splits = text_splitter.split_documents(pages)
# 生成向量(embedding)并存入数据库
embedding = ModelScopeEmbeddings(model_id=MODEL_ID)
db = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=PERSIST_DIRECTORY
)
# 持久化数据库
db.persist()
return db
def querying(query, history):
db = None
if not os.path.exists(PERSIST_DIRECTORY):
# 向量数据库不存在则创建
db = create_db()
else:
# 载入已有的向量数据库
embedding = ModelScopeEmbeddings(model_id=MODEL_ID)
db = Chroma(persist_directory=PERSIST_DIRECTORY, embedding_function=embedding)
# chat模型
llm = AzureChatOpenAI(
openai_api_version="2023-05-15",
azure_deployment="gpt35-16k",
model_version="0613",
temperature=0
)
# chat缓存,用于保持聊天记录
memory = AnswerConversationBufferMemory(memory_key="chat_history", return_messages=True)
# chat
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=db.as_retriever(search_kwargs={"k": 7}),
chain_type='stuff',
memory=memory,
return_source_documents=True,
)
result = qa_chain({"question": query})
print(result)
return result["answer"].strip()
# gradio
iface = gr.ChatInterface(
fn = querying,
chatbot=gr.Chatbot(height=1000),
textbox=gr.Textbox(placeholder="逻辑是谁?", container=False, scale=7),
title="三体问答机器人",
theme="soft",
examples=["简述一下黑暗森林法则",
"程心最后和谁在一起了?"],
cache_examples=True,
retry_btn="重试",
undo_btn="撤回",
clear_btn="清除",
submit_btn="提交"
)
iface.launch(share=True)
实现效果

参考资料
- https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview
- https://python.langchain.com/docs/modules/data_connection/
- https://www.gradio.app/guides/creating-a-chatbot-fast
Comments | NOTHING